Tensor Implementation (CPU)
Structure
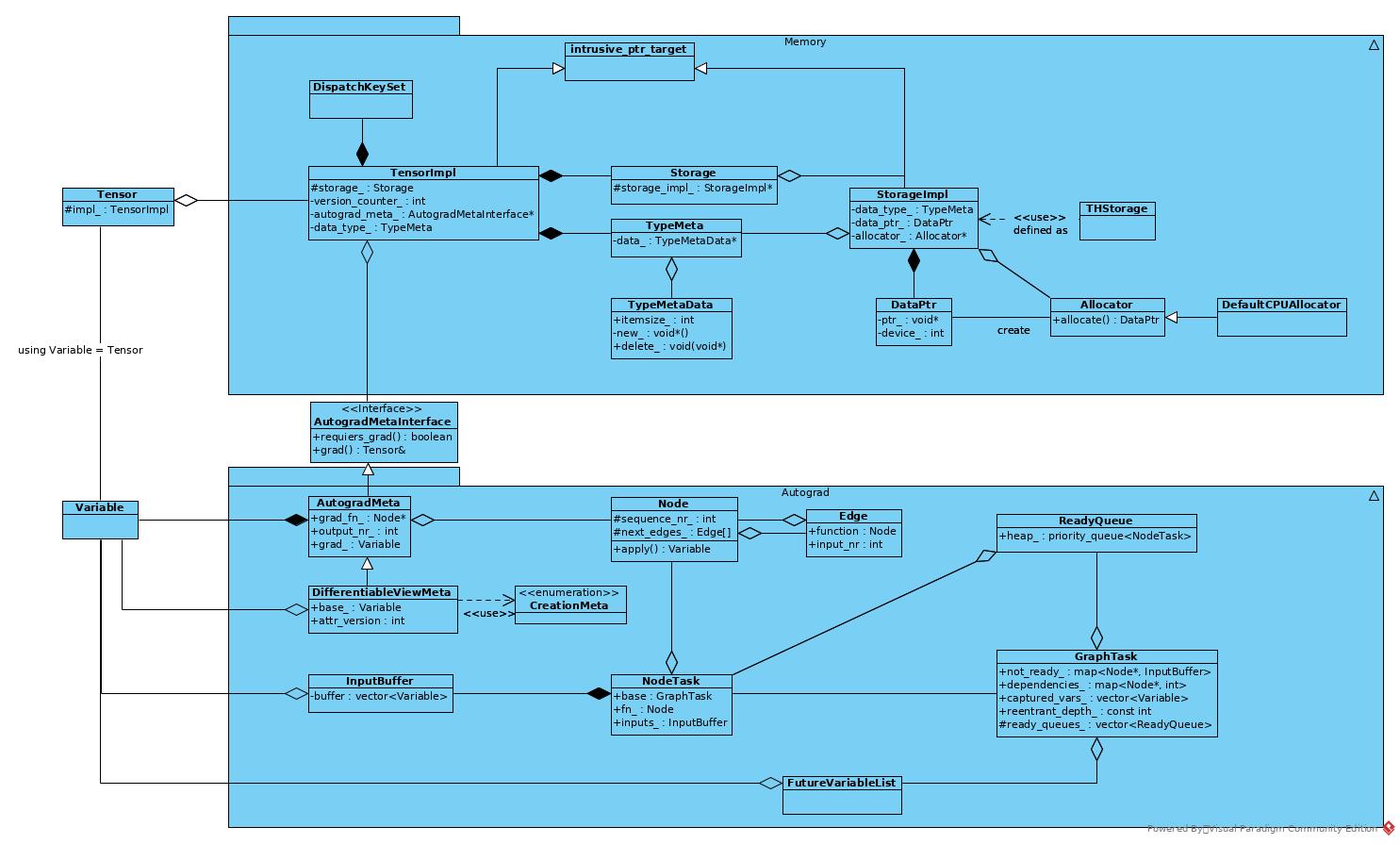
- Tensor is a wrapper class, it does not provide actual implementation.
- The functions of Tensor implemented in TensorImpl.
- The functions of TensorImpl could be grouped into 3 categories:
- For memory storage, implemented in Storage class.
- For autograd engine, key class is AutogradMeta.
- Shortcut of torch functions (e.g. torch::add and Tensor.add)
Memory
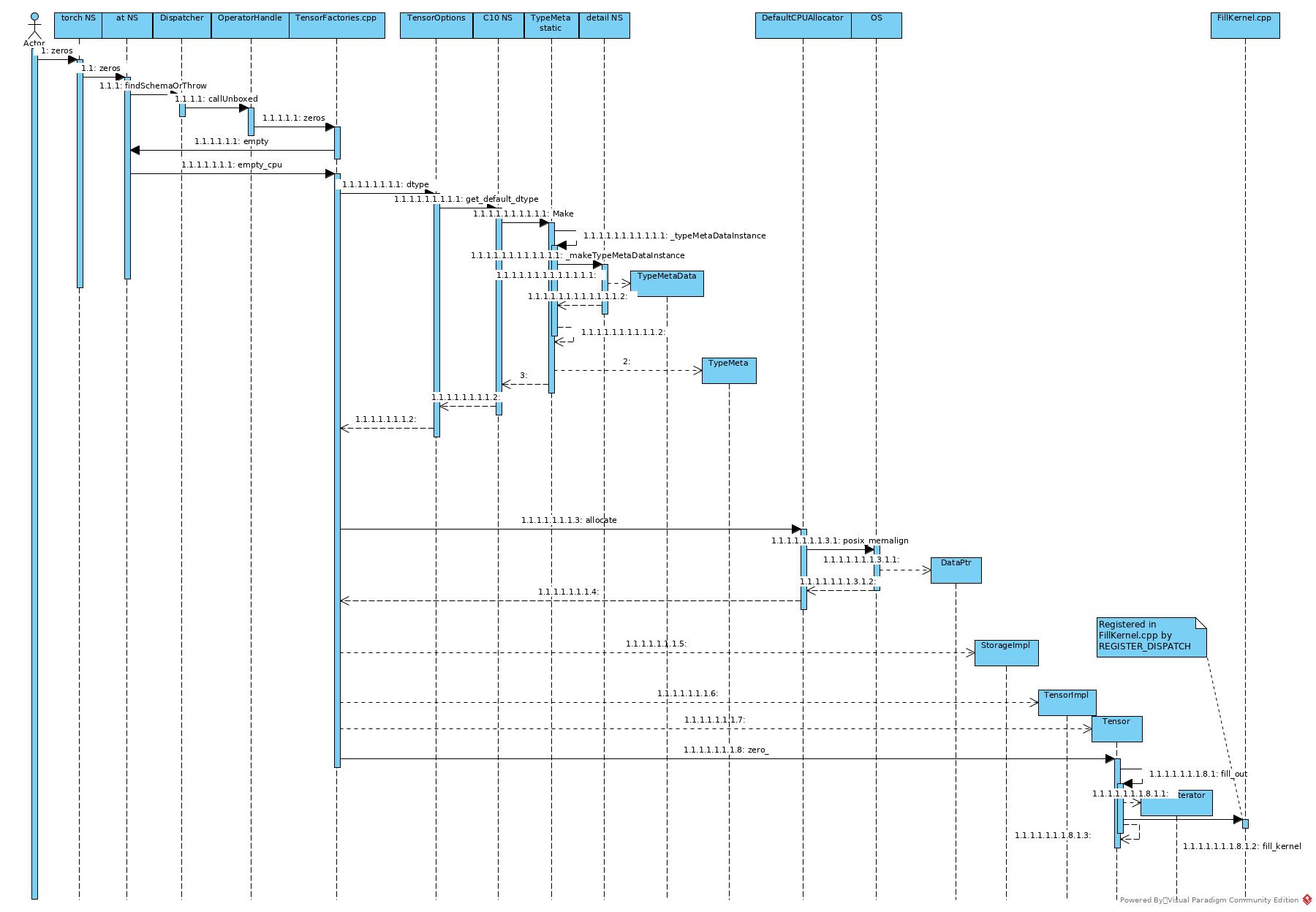
- Dispatcher dispatched the zeros to native cpu handle: zeros defined in TensorFactories.cpp
- To create an empty tensor.
- To decide type meta:
- type element size
- Newer and Deleter_
- The TypeMeta is still a wrapper class, it wraps a TypeMetaData pointer.
- The default dtype is a static object, the TypeMetaData member is a raw pointer, and the get/create functions return object instead of smart pointer or reference. There is no cost of deep clone of TypeMetaData, while it is still cost of object copy.
- Return TypeMeta of float + CPU.
- Get CPU allocator as allocator.
- Allocate dataptr by posix library. There is alternative to allocate large SHM file and allocate dataptr from SHM.
- Create StorageImpl by above TypeMeta, dataptr and allocator (for delete).
- Create Tensor by above StorageImpl
- Set the dispatcher key of the Tensor as CPU
- Call Tensor.zero to fill the Tensor with 0s
- Dispatcher dispatched the function to fill_kernel defined in FillKernel.cpp
- The kernel implements fill by vector instructions.
In general, to create a all zeros tensor:
- Decide type meta to dispatch to proper allocator.
- Decide dispatcher key to dispatch to proper fill kernel
Ref:
Autograd
Forward
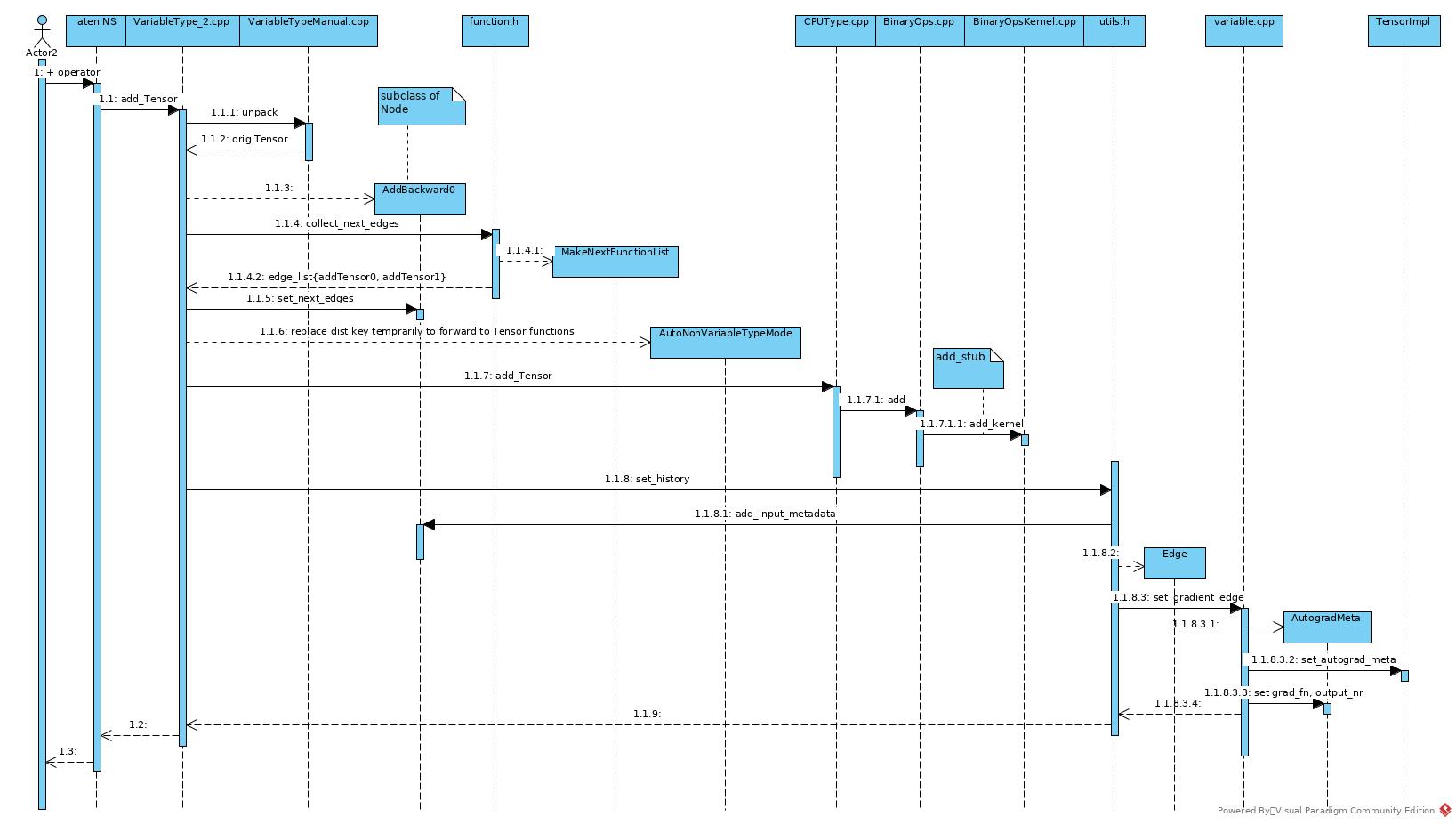
- Before add forward execution, prepare the Variable for backward in advance.
- Find backward kernel AddBackward0
- Create Node with backward kernel
- Set addends as next edges of current Node
- Call CPU kernel for add operation
- Set the add result as input of current Node
- Add the Node into the add_result_tensor.autogradMeta
Backward
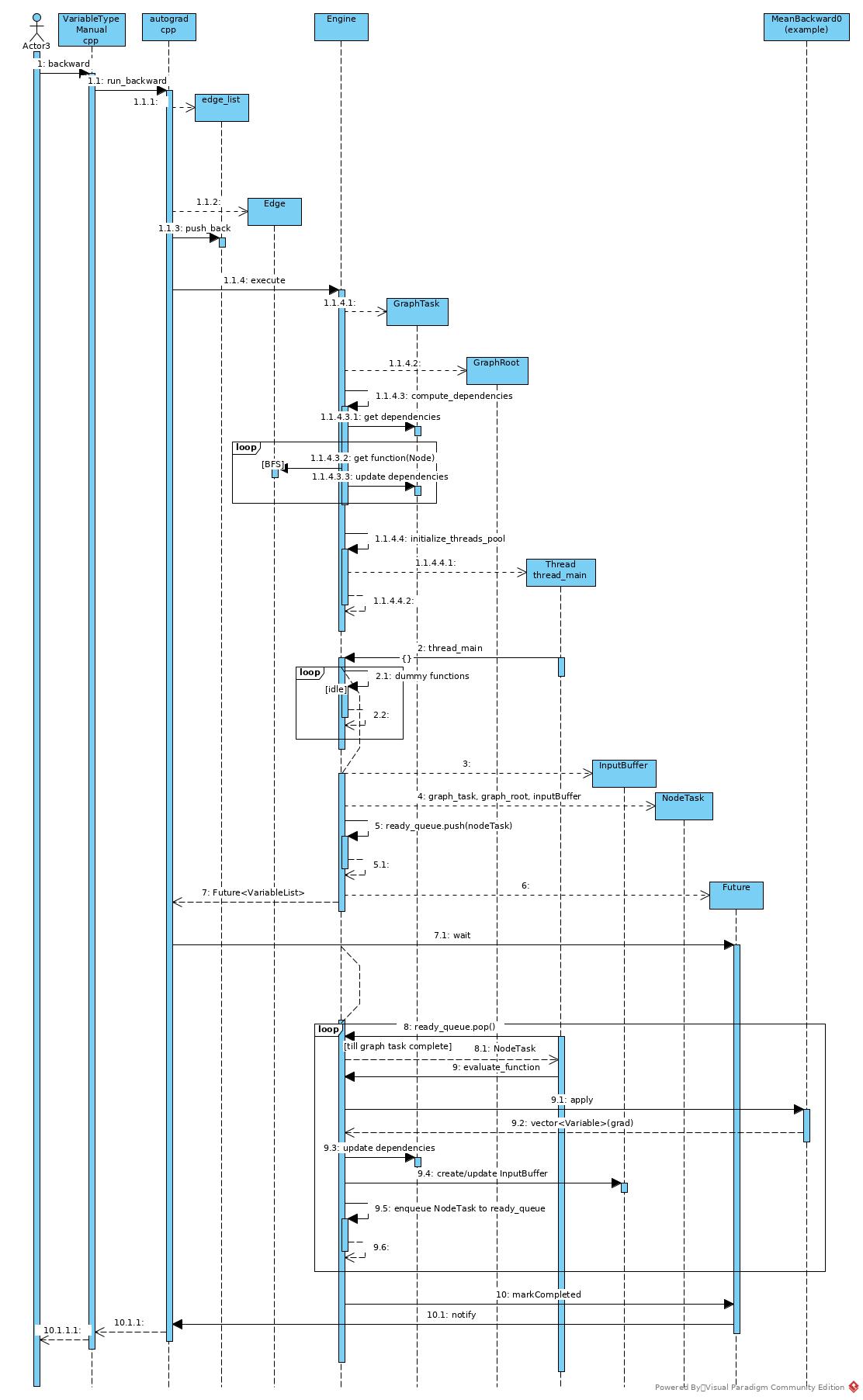
- Get root Edge. An Edge includes a Node pointer and a sequence number. A Node includes a backward function and next edges.
- Execute backward DAG with root Edge and root grad outputs.
- Create GraphTask and GraphRoot.
- GraphRoot is a special Node, which defines no actual backward function.
- GraphTask keeps all Node to be executed, storing in not_ready map or dependencies map.
- Engine traverses the graph by Node –> Edge –> Node –> … –> Leaf. Engine traverses the graph in BFS or topology order and keeps NodeTask in maps mentioned above.
- If execution thread pool has not been initialized, create the thread pool
- When there is no outstanding task in local ready_queue, just run dummy task.
- Create NodeTask with GraphTask mentioned above and push into local ready_queue and return Future
- Working thread detects the ready GraphTask and turns from idle state into working state
- Working thread execute kernel of current NodeTask
- Get all dependent NodeTask of current NodeTask by its edge_list.
- Check dependencies of current GraphTask, if dependent Node has dependent-number == 0, remove it from dependencies and push corresponding NodeTask into thread local ready_queue.
- Check not_ready map of current GraphTask, if dependent Node is ready, erase it from not_ready map and push the task into thread local ready_queue.
- If a NodeTask that was in dependencies_ had reached (dependent-number == 0), push it into not_ready
- If no outstanding task in GraphTask remained, mark the GraphTask as Complete
- Notify caller of backward that is waiting on Future
Key Files
- aten/src/ATen/core/Variadic.h
- aten/src/ATen/core/dispatch/Dispatcher.h
- aten/src/ATen/core/Tensor.cpp
- aten/src/ATen/native/BinaryOps.cpp
- aten/src/ATen/native/TensorFactories.h
- aten/src/Aten/native/TensorFactories.cpp
- aten/src/ATen/native/cpu/BinaryOpsKernel.cpp
-
aten/src/ATen/templates/TensorBody.h
- c10/core/TensorOptions.h
- c10/core/ScalarType.h
- c10/core/Scalar.h
- c10/core/DispatchKeySet.h
- c10/core/Allocator.h
-
c10/core/TensorImpl.cpp
- torch/include/c10/core/TensorImpl.h
- torch/include/c10/core/Storage.h
-
torch/include/c10/core/StorageImpl.h
- torch/csrc/autograd/variable.h
- torch/csrc/autograd/variable.cpp
- torch/csrc/autograd/VariableTypeManual.cpp
- torch/csrc/autograd/input_buffer.h
- torch/csrc/autograd/edge.h
- torch/csrc/autograd/engine.h
- torch/csrc/autograd/engine.cpp
- torch/csrc/autograd/function.h
- torch/csrc/autograd/autograd.cpp
- torch/csrc/autograd/functions/utils.h
- torch/csrc/autograd/functions/basic_ops.h
- torch/csrc/autograd/generated/Functions.cpp
- torch/csrc/autograd/generated/Functions.h
- torch/csrc/autograd/generated/variable_factories.h
- torch/csrc/autograd/generated/VariableTypeEverything.cpp
Use Case
Take following block as example:
Tensor t0 = torch::rand({2, 2}, TensorOptions().requires_grad(true));
Tensor t1 = torch::rand({2, 2}, TensorOptions().requires_grad(true));
Tensor a = torch::mm(t0, t1);
Tensor b = a + t1;
std::cout << "x add" << std::endl;
Tensor c = b + t0;
Tensor d = torch::sin(c);
Tensor e = d.mean();
e.backward();
Forward Phase
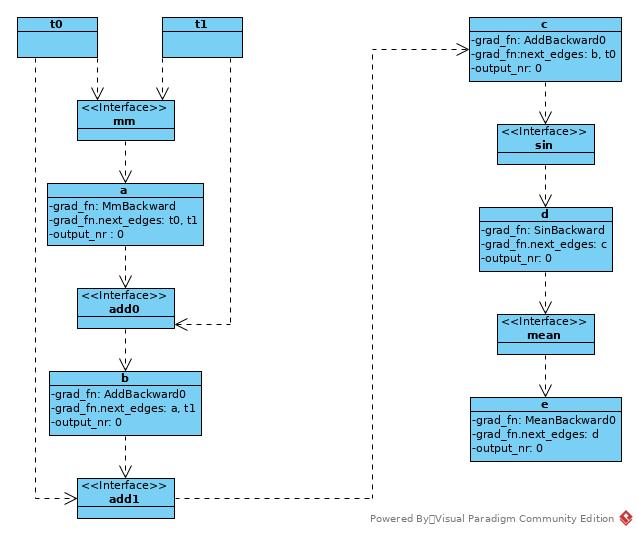
In forward phase, the operation result Variable remembers the backward function and set forward operation input Variables as next edges in backward phase.
Backward Phase
Initiation
Prepare GraphTask and GraphNode for task execution.
auto Engine::execute(const edge_list& roots,
const variable_list& inputs,
bool keep_graph,
bool create_graph,
const edge_list& outputs) -> variable_list {
// ...
auto graph_task = std::make_shared<GraphTask>(
keep_graph,
create_graph,
worker_device == NO_DEVICE ? 0 : total_depth + 1);
auto graph_root = std::make_shared<GraphRoot>(roots, inputs);
// ...
}
After initiation:
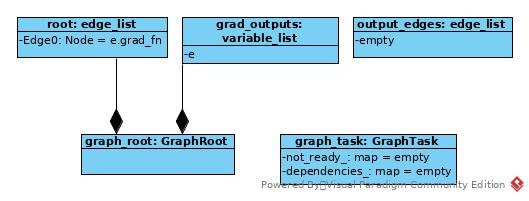
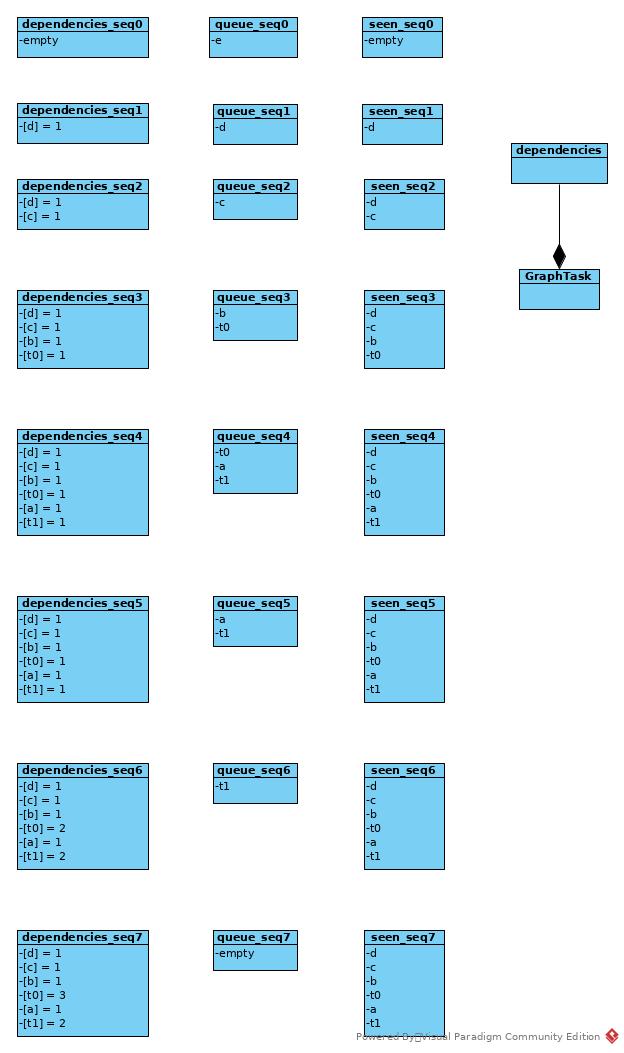
Compute Dependencies
auto Engine::compute_dependencies(Node* root, GraphTask& task) -> void {
std::unordered_set<Node*> seen;
std::vector<Node*> queue { root };
auto& dependencies = task.dependencies_;
while (!queue.empty()) {
auto fn = queue.back(); queue.pop_back();
for (const auto& edge : fn->next_edges()) {
if (auto next_ptr = edge.function.get()) {
dependencies[next_ptr] += 1;
const bool was_inserted = seen.insert(next_ptr).second;
if (was_inserted) queue.push_back(next_ptr);
}
}
}
}
The process of BFS:
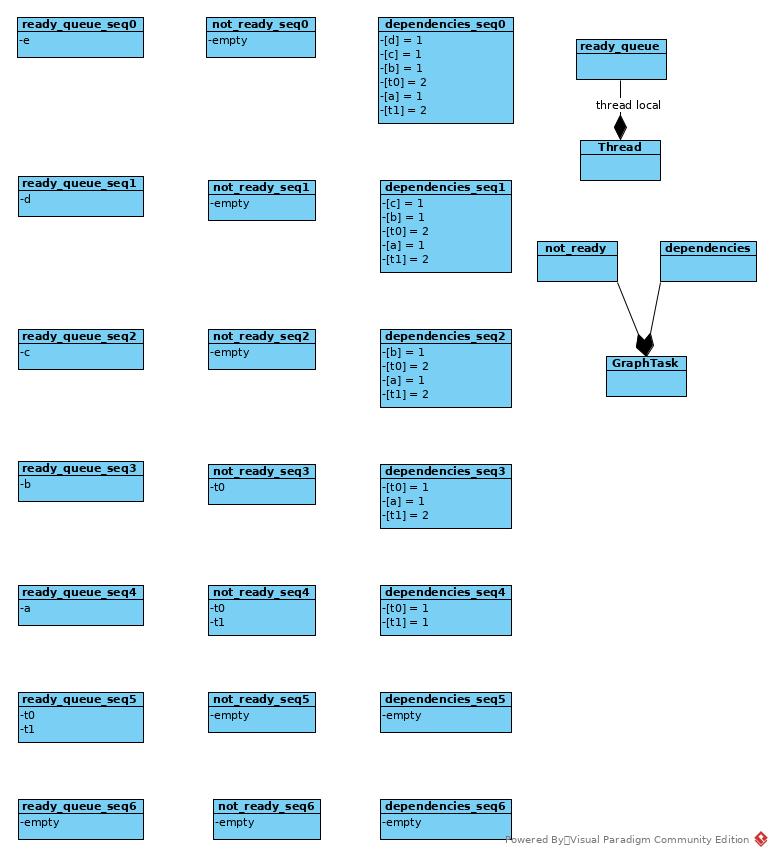
Execution
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs) {
const auto opt_parent_stream = (*func).stream(c10::DeviceType::CUDA);
c10::OptionalStreamGuard parent_stream_guard{opt_parent_stream};
auto outputs = call_function(graph_task, func, inputs);
auto& fn = *func;
int num_outputs = outputs.size();
if (num_outputs == 0) {
return;
}
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (int i = 0; i < num_outputs; ++i) {
auto& output = outputs[i];
const auto& next = fn.next_edge(i);
bool is_ready = false;
auto& dependencies = graph_task->dependencies_;
auto it = dependencies.find(next.function.get());
if (--it->second == 0) {
dependencies.erase(it);
is_ready = true;
}
auto& not_ready = graph_task->not_ready_;
auto not_ready_it = not_ready.find(next.function.get());
if (not_ready_it == not_ready.end()) {
InputBuffer input_buffer(next.function->num_inputs());
// Accumulates into buffer
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
auto& queue = ready_queue(input_buffer.device());
queue.push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
} else {
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
} else {
auto &input_buffer = not_ready_it->second;
// Accumulates into buffer
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
auto& queue = ready_queue(input_buffer.device());
queue.push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
not_ready.erase(not_ready_it);
}
}
}
}
The process of topology DAG traverse
Detach
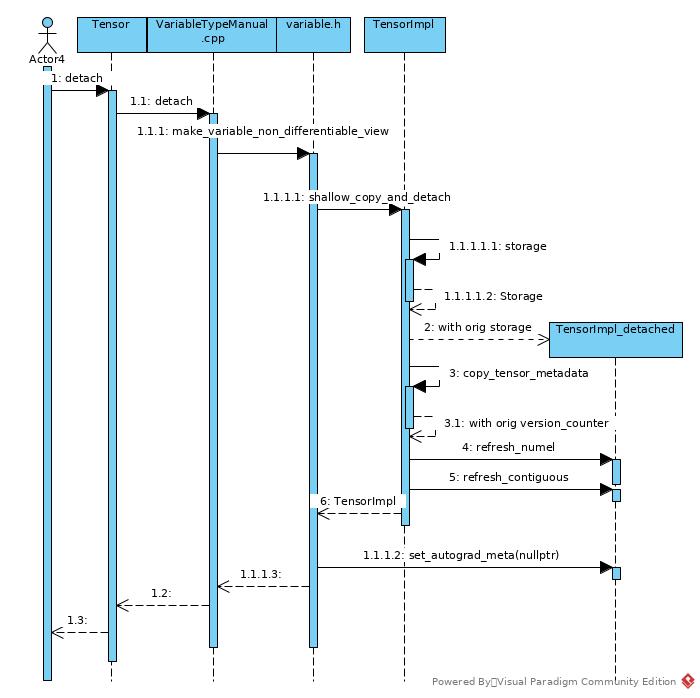
Tensor.detach() implements a shallow clone of original Tensor. The detached Tensor is invalid to grad immediately after detach() as its AutogradMeta has been set as nullptr.
Some Codes
intrusive_ptr.h
pytorch defines intrusive_ptr as an alternative to shared_ptr for:
- It has better performance because it does the refcounting intrusively (i.e. in a member of the object itself). Why better performance?
- It provides intrusive_ptr only by make_intrusive, which newed a heap object. Otherwise, the stack object would be detected as the refcount == 0 and therefore be released.
intrusive_ptr_target
The type that could be wrapped by intrusive_ptr should inherit class intrusive_ptr_target.
class C10_API intrusive_ptr_target {
It provides mutable atomic size_t type members for concurrent counting.
mutable std::atomic<size_t> refcount_;
mutable std::atomic<size_t> weakcount_;
The counters are not public members, define friend function to grant accession.
template <typename T, typename NullType>
friend class intrusive_ptr;
friend inline void raw::intrusive_ptr::incref(intrusive_ptr_target* self);
Define destructor as protected to prevent end user from deleting the target.
protected:
// protected destructor. We never want to destruct intrusive_ptr_target*
// directly.
virtual ~intrusive_ptr_target() {
Define the function that executes the real cleanup job as private virtual:
private:
virtual void release_resources() {}
extra cleanup virtual function
intrusive_ptr
Define a null type for nullptr with noexcept constexpr static function singleton.
namespace detail {
template <class TTarget>
struct intrusive_target_default_null_type final {
static constexpr TTarget* singleton() noexcept {
return nullptr;
}
};
Why an extra null type defined?
The intrusive_ptr class defined as:
template <
class TTarget,
class NullType = detail::intrusive_target_default_null_type<TTarget>>
class intrusive_ptr final {
Declare the inner resource:
TTarget* target_;
Allow other types specification of intrusive_ptr as friend for implicit conversion that was allowed between types of wrapped pointer.
template <class TTarget2, class NullType2>
friend class intrusive_ptr;
Add reference counter. If the counter reached 0, report error as 0 reference followed by object destruction. intrusive_ptr is friend class of corresponding target type T.
void retain_() {
if (target_ != NullType::singleton()) {
size_t new_refcount = ++target_->refcount_;
TORCH_INTERNAL_ASSERT_DEBUG_ONLY(
new_refcount != 1,
"intrusive_ptr: Cannot increase refcount after it reached zero.");
}
}
Remove reference of current object. NullType::singleton() used.
void reset_() noexcept {
if (target_ != NullType::singleton() && --target_->refcount_ == 0) {
const_cast<std::remove_const_t<TTarget>*>(target_)->release_resources();
if (--target_->weakcount_ == 0) {
delete target_;
}
}
target_ = NullType::singleton();
}
Declare the constructor as private explicit, as intrusive_ptr is only allowed to be created by make_intrusive with counter management.
explicit intrusive_ptr(TTarget* target) noexcept : target_(target) {}
Type alias:
public:
using element_type = TTarget;
Default constructor set target as NullType. Maybe for container usage.
intrusive_ptr() noexcept : intrusive_ptr(NullType::singleton()) {}
The move constructor, set moved in rhs.target as NullType. Why not just swap?
intrusive_ptr(intrusive_ptr&& rhs) noexcept : target_(rhs.target_) {
rhs.target_ = NullType::singleton();
}
If target pointers are convertible, the intrusive_ptr objects are convertible. The moved-in object rhs has nullptr set.
template <class From, class FromNullType>
/* implicit */ intrusive_ptr(intrusive_ptr<From, FromNullType>&& rhs) noexcept
: target_(detail::assign_ptr_<TTarget, NullType, FromNullType>(rhs.target_)) {
static_assert(
std::is_convertible<From*, TTarget*>::value,
"Type mismatch. intrusive_ptr move constructor got pointer of wrong type.");
rhs.target_ = FromNullType::singleton();
}
Copy constructor, increase reference counter.
intrusive_ptr(const intrusive_ptr& rhs) : target_(rhs.target_) {
retain_();
}
Destructor, decrease reference counter, release resources if no more references.
~intrusive_ptr() noexcept {
reset_();
}
The assignment operator:
- tmp is created by copy constructor mentioned above. tmp has target set, rhs has nullptr set.
- The copy-and-swap idiom.
- At the end of operator=(), destructor of tmp takes responsibility of counting and resource management.
- The first operator=() reuse implementation of the second one.
intrusive_ptr& operator=(intrusive_ptr&& rhs) & noexcept { //zf: Why specialize TTarget? return operator=<TTarget, NullType>(std::move(rhs)); } template <class From, class FromNullType> intrusive_ptr& operator=(intrusive_ptr<From, FromNullType>&& rhs) & noexcept { static_assert( std::is_convertible<From*, TTarget*>::value, "Type mismatch. intrusive_ptr move assignment got pointer of wrong type."); intrusive_ptr tmp = std::move(rhs); swap(tmp); return *this; }The class intrusive_ptr overloaded bool() operator. It’s seemed not a good practice, while simple and straightforward.
operator bool() const noexcept {
return target_ != NullType::singleton();
}
To construct intrusive_ptr object, end-user must take use of static function make. That is why constructor has been declared as private.
template <class... Args>
static intrusive_ptr make(Args&&... args) {
auto result = intrusive_ptr(new TTarget(std::forward<Args>(args)...));
// We can't use retain_(), because we also have to increase weakcount
// and because we allow raising these values from 0, which retain_()
// has an assertion against.
++result.target_->refcount_;
++result.target_->weakcount_;
return result;
}
Other operators have been defined as non-member functions.
Tensor.h Template
Some Knowledge
Anonymous Namespace
- The definition is treated as a definition of a namespace with unique name and a using-directive in the current scope that nominates this unnamed namespace.
- This is the same as the C way of having a static global variable or static function but it can be used for class definitions as well.
- It also avoids making global static variable.
- Usage in aten/src/ATen/core/op_registration/README.md
template keyword
template<class Key, class Value, class Iterator>
class DictEntryRef final {
public:
explicit DictEntryRef(Iterator iterator)
: iterator_(std::move(iterator)) {}
Key key() const {
return iterator_->first.template to<Key>();
}
//...
const
const DictEntryRef<Key, Value, Iterator>& operator*() const {
return entryRef_;
}
entryRef_ is not a const object. Declaring the return type as const enables declaring the function as const
copy-and-swap
class Blob final : public c10::intrusive_ptr_target {
public:
Blob() noexcept : meta_(), pointer_(nullptr), has_ownership_(false) {}
~Blob() {
Reset();
}
Blob(Blob&& other) noexcept : Blob() {
swap(other);
}
void Reset() {
free_();
pointer_ = nullptr;
meta_ = TypeMeta();
has_ownership_ = false;
}
void swap(Blob& rhs) {
using std::swap;
swap(meta_, rhs.meta_);
swap(pointer_, rhs.pointer_);
swap(has_ownership_, rhs.has_ownership_);
}
}
The copy-and-swap idiom application:
Blob& operator=(Blob&& other) noexcept {
Blob(std::move(other)).swap(*this);
return *this;
}
The object other is moved into the operator=() function, this function take responsibility of resource of other and self. A pure swap is not able to guarantee the noexcept constraint.
- A Blob created by copy constructor. Name the object tmp. Object tmp holds pointer_ of other. Object other holds pointer_ of nullptr. Object other then destructed at the end of copy constructor.
- Swap objects tmp and self. Object self holds pointer of original other, object tmp holds pointer of original self.
- Object tmp destructed at the end of operator=(), pointer_ hold by original self released.
- The temporary object has been created for destruction of original self resources.
- Even if swap or copy constructor is not noexcept, this temporary object guarantees destruction of resources hold by other or self.
Variadic Templates
An example (torch/aten/src/ATen/core/Variadic.h)
template <typename... Args>
inline F& apply() {
return self();
}
template <typename T, typename... Args>
inline F& apply(T&& arg, Args&&... args) {
self()(std::forward<T>(arg));
if (self().short_circuit()) {
return self();
} else {
return apply(std::forward<Args>(args)...);
}
}