CUDA Programming
Threads Related
Terminology
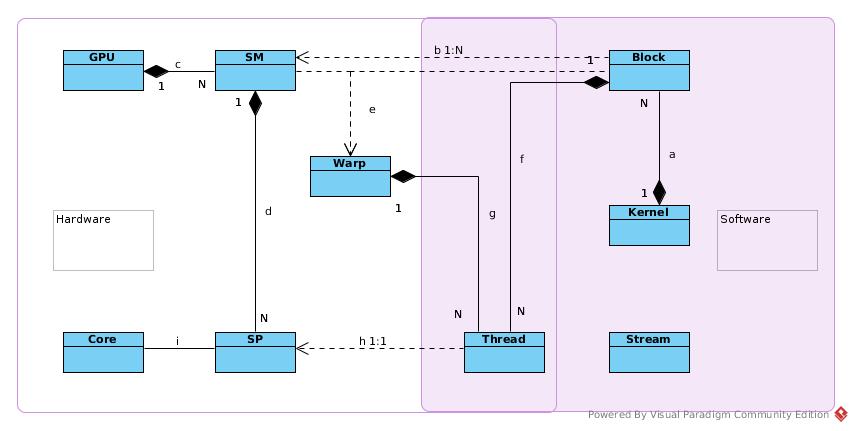
- a: A kernel is a unit of program that to be executed in GPU. A kernel can requires N thread blocks, each block is combined by same number of threads. Kernel is a software concept.
- b: Thread block is unit of SM scheduling. 1) A block can be assigned to only one SM. The hardware architecture and scheduling policy decide in which SM the block would be assigned. Block does not migrate. 2) Threads in the same block can communicate with each other via SHM, barrier or other synchronization primitives such atomic operations; as they reside in the same SM and have access to same cache, SHM or register file. 3) Number of Thread per block is concept to programmer. Threads in the same block may not run physically in parallel when resources (computing resource or memory access) is not ready.
- c: One GPU contains N SM. It is hardware concept.
- d: One SM contains N SP. It is hardware concept.
- e: Warp is unit of hardware scheduling. Threads in one warp executed in parallel physically. One Warp = 32 threads.
- f: A block contains a lots of threads (…/512/1024/or more). 1) A block/kernel assign tasks to threads by programming logic. 2) The threads in one block are assigned to one SM, and managed by Warp 3) SM/GPU schedules warp into SP according to it life cycle status.
- g: A Warp is combined by 32 threads. 1) A Warp is SIMT 2) Two Warps are MIMD, can do branching, loops, etc.
- h: SP is the hardware unit that actually executes thread. One thread per SP. SP does not control life cycle of thread.
- i: Core is alias of SP
*_A block would be executed after occupying block completed? That is something related to STREAM*_
Dynamic Parameters
In general, When discussing GPU performance, in most cases, we are talking about throughput. The throughput is often measured by Occupancy, and occupancy is measured by number of running Warps.
For certain GPU, the fixed parameters are:
- Number of SM
- Number of SP per SM
- Maximum number of blocks per SM
- Maximum number of threads per SM
- Maximum number of threads per Block
The dynamic parameters are
- Number of blocks
- Number of threads per block
Consequently:
- Total number of Threads = (Number of Thread per Block) * (Number of Block)
- Total number of Blocks = (Max Number of Block per SM) * (Number of SM)
For a certain kernel, Number of Blocks:
- It depends on max number of Block per GPU = (max number of Block per SM) * (Number of SM)
- (Number of Block per SM) <= Floor((Max number of Threads per SM) / (Number of Threads per Block))
- But it is OK to set (Number of blocks) > (Number of blocks per GPU). Although some of them are definitely not able to executed in parallel, this type of setting helps hide the potential latency.
Number of Thread per Block (When number of Block is not decided yet):
- Number of Thread per Block <= Max number of Thread per Block
- It decides Number of Block: (Total Number of Threads) / (Number of Thread per Block)
- It decides Number of Block per SM = Floor((Max number of Thread per SM) / (Number of Thread per Block)).
- When calculating Number of Warp per SM, the Number of Block never exceeds hardware capacity of SM.
- It decides Number of Warp per SM: (Block per SM) * (Number of Thread per Block) / 32 1) if (Number of Block per SM) <= (Max number of Block per SM), (Number of Warp per SM) = (Number of Block per SM) * (Number of Thread per Block) / 32 2) if (Number of Block per SM) > (Max Number of Block per SM), (Number of Warp per SM) = (Max number of Block per SM) * (Number of Thread per Block) / 32
Memory
Overview
Examples
Cardinality Sort
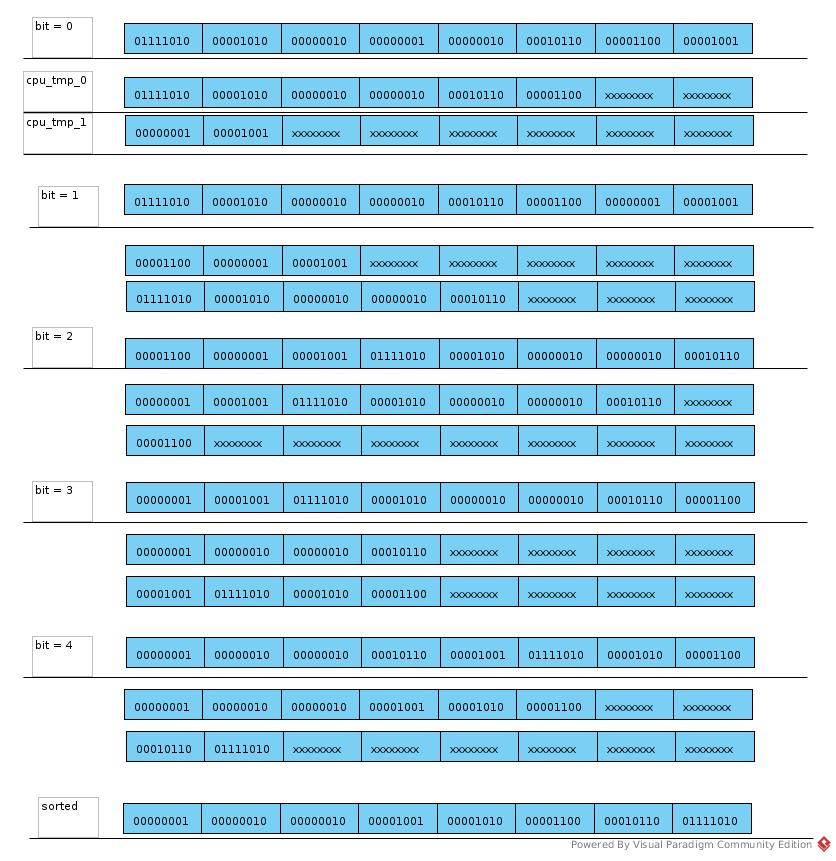
CPU Sort 1
The basic radix sort codes for CPU (Section 6.4.2)
__host__ void cpu_sort(u32 *const data, const u32 num_elements) {
static u32 cpu_tmp_O[NUM_ELEM];
static u32 cpu_tmp_1[NUM_ELEM];
for (u32 bit = 0; bit < 32; bit ++) {
u32 base_cnt_0 = 0;
u32 base_cnt_1 = 0;
for (u32 i = 0; i < num_elements; i ++) {
const u32 d = data[i];
const u32 bit_mask = (1 << bit);
if ( (d & bit_mask) > 0) {
cpu_tmp_0[base_cnt_1] = d;
base_cnt_1 ++;
} else {
cpu_tmp_0[base_cnt_0] = d;
base_cnt_0 ++;
}
}
for (u32 i = 0; i < base_cnt_0; i ++) {
data[i] = cpu_tmp_0[i];
}
for (u32 i = 0; i < base_cnt_1; i ++) {
data[base_cnt_0 + i] = cpu_tmp_1[i];
}
}
The process is like:
GPU Sort 1
Section 6.4.2
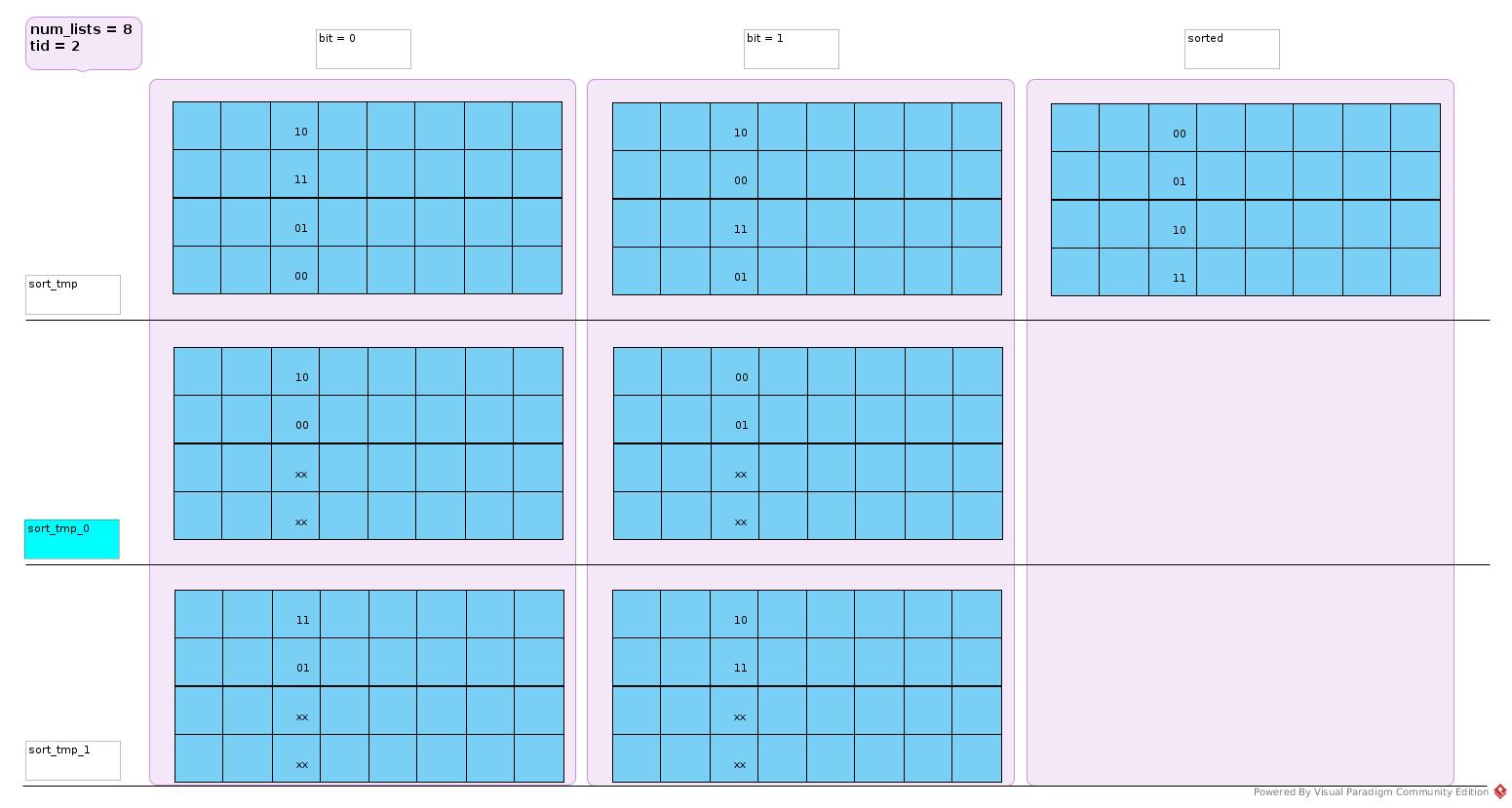
Sort with 2 Tmp Block
__device__ void radix_sort(u32 *const sort_tmp,
const u32 num_lists,
const u32 num_elements,
const u32 tid,
u32 *const sort_tmp_0,
u32 *const sort_tmp_1) {
for (u32 bit = 0; bit < 32; bit ++) {
u32 base_cnt_0 = 0;
u32 base_cnt_1 = 0;
for (u32 i = 0; i < num_elements; i += num_lists) {
const u32 elem = sort_tmp[i + tid];
const u32 bit_mask = (1 << bit);
if ((elem & bit_mask) > 0) {
sort _tmp_1[base_cnt_1 + tid] = elem;
base_cnt_1 += num_lists;
} else {
sort_tmp_0[base_cnt_0 + tid] = elem;
base_cnt_0 += num_lists;
}
}
for (u32 i = 0; i < base_cnt_0; i+= num_lists) {
sort_tmp[i + tid] = sort_tmp_0[i + tid];
}
for (u32 i = 0; i < base_cnt_1; i += num_lists) {
sort_tmp[base_cnt_0 + i + tid] = sort_tmp_1[i + tid];
}
}
__synchthreads();
}
Each thread sort a column of raw data that represented in 2D matrix:
Sort with 1 Tmp Block
Just replace sort_tmp_0 with sort_tmp as there is no overlapping case.
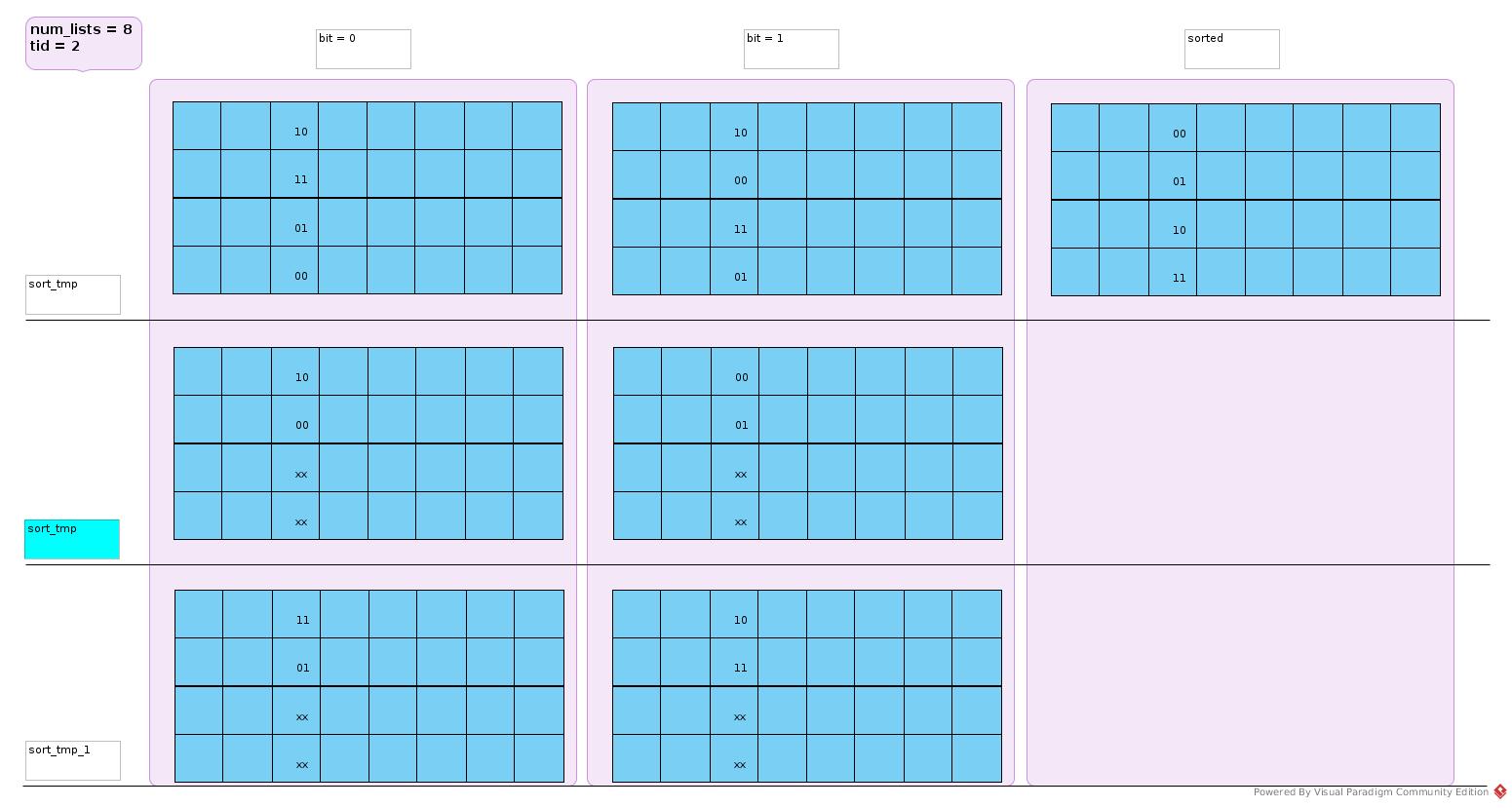
Merge with Single Thread
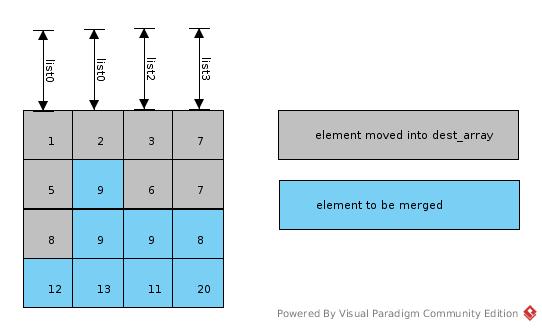
Page 127
Imagine src_array as 2D matrix, num_lists = column_number; list_indexes[list] = row_index; list = column_index.
One column had been sorted by one GPU thread.
In merge phase as shown in above figure, when i = 8:
- list = 0, list_indexes[list] = 3, src_index = (3, 0), data = 12
- list = 1, list_indexes[list] = 1, src_index = (1, 1), data = 9
- list = 2, list_indexes[list] = 2, src_index = (2, 2), data = 9
- list = 3, list_indexes[list] = 2, src_index = (2, 3), data = 8
min_val = 8, min_idx = 3, dest_array[8] = 8, list_indexes[3] = 3
Merge in Parallel
Merge Sort
select_samples_gpu_kernel
sample_data is an input argument.
Is it in SHM or Global Memory?
sort_samples_xpu
Both CPU and GPU provides library for this simple sort.
While cooperation of threads and challenge to cache covered benefits of parallel in GPU. This task is more straightforward to be executed in CPU, and with better performance.
Prefix Sum Calculation
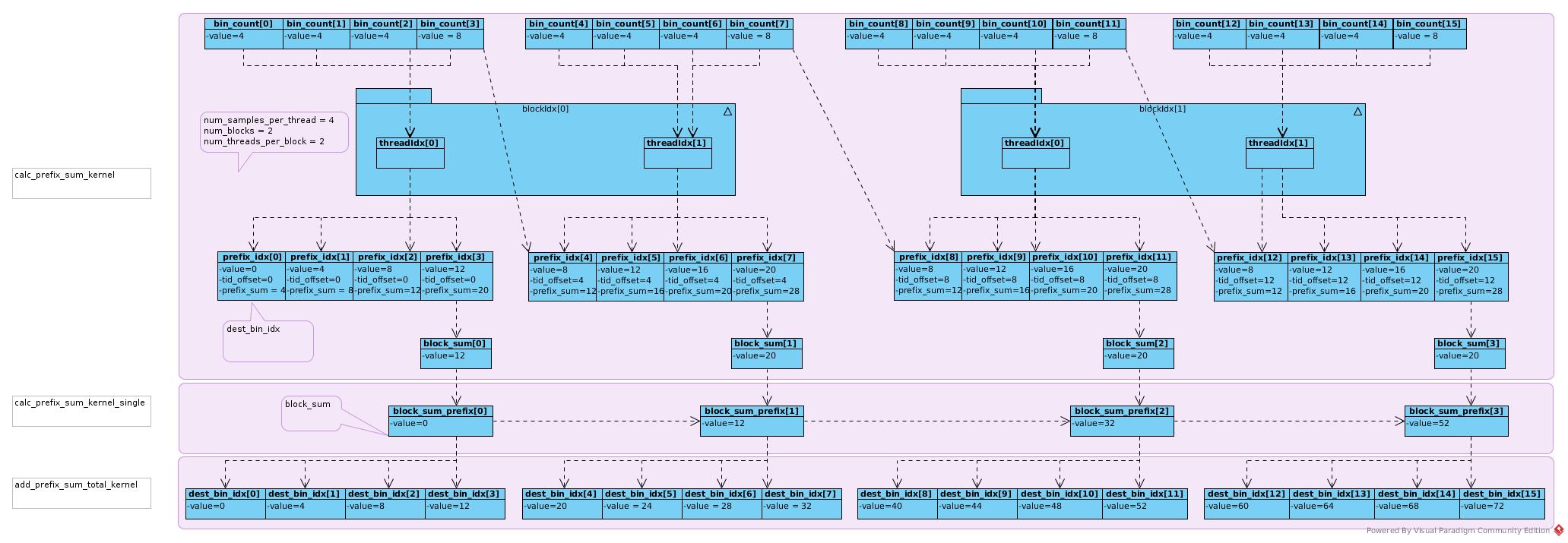
The last bin_count of current block thread would be added to first prefix_idx of the next block thread, as this number would not be counted in sum/prefix of current block thread.
Tips
- Register is the best candidate to storage for its access performance, with 2 limitations: 1) It is NOT shared between threads 2) Too many registers per thread may harm capacity of Warp
- SHM 1) If each thread of Warp accesses a separate bank address, the certain operation of the Warp could be executed in one cycle 2) If more than one threads access to the same bank address, they would be executed sequentially 3) If each thread of the Warp reads the same bank address, the read of all threads could be executed in one cycle
- Quick sort is not the best for GPU as it 1) Recursion is not supported in CUDA prior to 2.x 2) Branches are divergence, not good for GPU
- The function invocation costs registers for stack, so merge functions into one function is a reasonable way to reduce register cost.
- Constant memory 1) Constant memory is part of global memory. 2) There is no special reserved constant memory block 3) It is read-only for GPU, writable for CPU 4) It is cached (where?) 5) It supports broadcasting a single value to all elements within a warp. It provides L1 cache speed 6) If a constant is really a literal value, it is better to define it as literal value using #define 7) Sometimes, compiler may transfer constant var into literal var 8) On Fermi, L1 cache and constant memory access speeds are in same level
- Coalesced access 1) If we have a one-to-one sequential and aligned access to memory, the address accesses of each thread are combined together and a single memory transaction is issued. 2) Replace cudaMalloc with cudaMallocPitch 3) So, data often organized by columns instead of rows as that in CPU case 4) Array of structure would be split into separate arrays: abcdabcdabcdabcd ==> aaaabbbbccccdddd. The later is better for Warp of 4 threads to execute SISD
- Index calculation is sometimes costly, some multiplications and additions and moves
- Global Memory question & answer 1) Performance of almost sorted data is better as each bin has almost the same number of data to be sorted, that makes each thread have almost the same workload. 2) In radix sort of each bin, the layout of data elements to be sorted is like one row per thread, that failed coalesced access.
- Constant memory, Global memory, L2 cache?
- Difference between L1 cache and SHM, as they have similar performance?
Using CUDA in Practice
- Fermi designers believe the programmer is best placed to make use of the high-speed memory that can be placed close to the processor, in this case, the SHM on each SM
- OpenMP and MPI are not good fit for GPU, but OpenMP is relatively better
- Selecting an algorithm that is appropriate to hardware and getting the data in the correct layout is often key to good performance on GPU.
- Branching within a warp in this way causes the other threads to implicitly wait at the end of if statement (page 216 PDF)
- __proc returns 1s in input argument in bit format
- The blocks, and the warps within those blocks, may execute in any order. The if (threadIdx.x == 0) && (blockIdx.x == 0) does not synchronize implicitly
- Local storage on Fermi is L1 cache and global memory on the earlier-generation GPUs. On Fermi, pushing more data into the L1 cache reduces the available cache space for other purposes.
- Multiplication costs many cycles, which may stall the instruction stream. So index of array is not good practice, replace it with pointer++ is much better
- Loop unrolling –> instruction level parallelism, but more registers required
- How number of registers per thread affects number of block per SM?
- Where are data in registers when corresponding threads are stalled and other Warp of thread are scheduled?
- Threads in one Block execute same instructions, Warp decides if they are executed or stalled. Is that right?
- Number of blocks VS number of threads per SM
- Transfer performance: PCIe transfer performance, decided by PCIe hardware performance
- Stream 0 is the default stream. This is a synchronized stream that helps significantly when debugging an application but is not the most efficient use of GPU.
- Asynchronous stream decreases synchronization needed for an asynchronous operation.
- The registers overflow to local memory which harms performance. Declare it as shared to make them overflow the SHM.
- Stack frame often overflows to local memory to harm the performance. Declare function as forceinline force the function unroll in compiling.
- When Issue Stalls are in small percentage, increase available Warp does not help occupancy.
- Multiple streams are useful in that they allow some overlap of kernel execution with PCI-E transfers
- With a single PCI-E transfer engine enabled, we have just a single queue for all the memory transfers in the hardware. Despite being in separate streams, memory transfer requests feed into a single queue on Fermi and earlier hardware. Thus, the typical workflow pattern of transfer from host to device, invoke kernel, and then transfer from device to host creates a stall in the workflow. The transfer out of the device blocks the transfer into the device from the next stream. Thus, all streams actually run in series
- You need N sets of host and device memory, where N is the number of streams you wish to run. When you have
multiple GPUs, this makes a lot of sense, as each GPU contributes significantly to the overall result.
However, with a single-consumer GPU the gain is less easy to quantify. It works well only where either
the input or output of the GPU workload is small in comparison to one another and the total transfer
time is less than the kernel execution time
Multi-CPU and Multi-GPU Solutions
- The issue of cache coherency is what limits the maximum number of cores that can practically cooperate on a single node
- As soon as a core from socket 1 tries to access a memory address from socket 2, it has to be serviced by socket 2, as only socket 2 can physically address that memory. This is called nonuniform memory access (NUMA)
- CPU processes use separate memory space. GPU Blocks access a common address space on GPU global memory
- Multiple GPUs can communicate to one another on the same host, using host memory, or via PCIe bus peer-to-peer communication model.
Streams
- Streams are virtual work queues on GPU.
- They are used for asynchronous operations, i.e., when you would like the GPU to operate separately from CPU
- The default memory copies to and from the host or device implicitly cause a synchronization point.
- Asynch-stream/push_to_queue/multi-stream per GPU
Optimizing You Application
STRATEGY 1: PARALLEL/SERIAL GPU/CPU PROBLEM BREAKDOWN
Could the problem be broken down? How many blocks could it be split? The strategy is often data based or output data based.
Dependencies
- Block of codes running in CPU often keep it sequence. In GPU, it may be broken down into parallel parts by GPU automatically
- Loop fusion
1) May reduce iteration number –> reduce branch
2) Merge independent calculation –> reduce iteration number –> but reduce possible parallel if threads resource is enough to execute them in parallel
3) Split data into blocks that could be hold by SHM or registers in calculation.
Dataset
The major question for GPU is not so much about cache, but about how much data can you hold on a single card. Transferring data to and from the host system is expensive in terms of compute time. You should overlap computation with data transfers.
STRATEGY 2: MEMORY CONSIDERATIONS
STRATEGY 3: TRANSFERS
Pinned memory
- The PCIe transfers in practice can only be performed using DMA-based transfer. Without pinned memory, CPU allocates locked memory in real time and then release it; which is CPU costly.
- Memory allocated on the GPU is by default allocated as page locked simply because GPU does not support swapping memory to disk.
Zero-copy memory
- If your application is arithmetically bound, zero-copy memory can be a very useful technique. It saves you the explicit transfer time to and from the device. In effect, you are overlapping computation with data transfers without having to do explicit stream management.
- This can also be used very effectively on systems where the host and GPU share the same memory space
- In effect, what happens with the zero-copy memory is we break both the transfer and the kernel operation into much smaller blocks, which execute them in a pipeline (Figure 9.17). The overall time is reduced quite significantly