Chapter08
Notes
8.1
- Plan-space methods are difficult to apply efficiently to stochastic sequential decision problem that are the focus of reinforcement learning.
8.3
In a planning context, exploration means trying actions that improve the model, whereas exploitation means behaving in the optimal way given the current model.
Exercises
8.1
Yes, it could be better than one-step Dyna-planning. For example, a multi-step expected Q learning could be a candidate.
- N-step Q learning is itself a bootstrapping algorithm,
- Make the policy as random policy start with (S,A)
- The Model = real environment in fact
- It has been proved that n-step Dyna-planning performs better than one-step planning
8.2
For a new or newly updated environment, the initial Model and Q failed to reflect real environment. The agent needs exploration to detect the relatively more prospective policies.
8.3
Two alternatives:
- The long path requires more explorations, and exploration means extra cost
- The path is easy to be found and exploration is waste
8.4
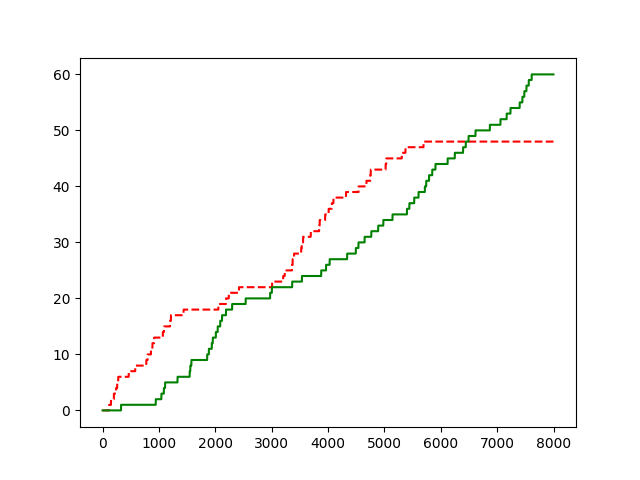
Total step = 8000, change model at step = 4000; red = dyna, green = dyna+
Move The Block
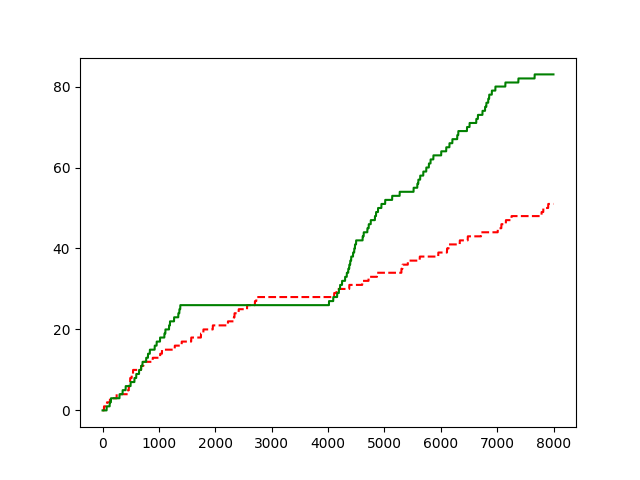
Shortcut
8.5
8.5.1
It requires another table for P(S’ | S, A). And Q(S,A) updated by maxa(∑s’’p(s’’|s’,a) * Q(s’, a))
8.5.2
As learning from real world and learning from model are separated, the speed of learning from model may lay back the changing of real world.
8.5.3
Adjust the ratio of environment learning and model learning
8.6
It would strengthen for sample updates over expected updates as
- Number of states that contributes little importance to expected update increases
- Estimated value of sample update has less gap to expected value
8.7
As random policy is similar to greedy policy with huge exploration factor, when b=1, the deterministic environment is more suitable for greedy policy with minor exploration factor. The random policy takes too much time exploring non-optimal candidates.
- The gap between on-policy and uniform increase when b increases
- The gap between on-policy and uniform increase when number of states increases
8.8
Not explicit test result: