#Chapter05
Notes
- Q or V? Why? How to remove model?
- Advantages of MC
- Bias and Bound and How to deal with it
- No bootstrap
- First-visit and Every-visit
- Exploring policy: how to meet the requirements
- MCES = Monte Carlo Exploring Starts
- DP converge? Converge to optimal?
5.1
- MC is used to learn v(s).
- Both first-visit and every-visit algorithm converge to unbiased expectation and standard deviation of error fall as (1 / n1/2)
- Estimation of state value is independent of that of other states. Which means:
- No bootstrap
- Just experiences, no Bellman equation.
- Can focus on certain states, ignoring others
- Advantages of MC:
- Learn from actual experience
- Learn from simulation
- Only states concerned to be estimated
5.2
- Given V(s) learned, the policy is to be determined by argmaxa∑ap(s’|s,a)(r + v(s’)), still the model p(s’|s,a) to be given. So, Q(s,a) is more directly choice for policy learning
- To learn Q(s,a), we’d better learn each action of a state to choose the best one for policy improvement.
While as MC could estimate Q(s,a) without considering Q(s,a’), esp in case of deterministic π, we need exploration.
- Exploration start is useful, but sometimes not practical
- Alternatives to assuring all state-action pairs are encountered
5.3
MCES:
- Start from random (s,a) pair
- Run episode from start pair to terminal state
- Record each (s,a) and corresponding reward for each step
- After each episode, update G for each (s,a); update Q for each (s,a); update π(s) for each step.
- By backward order
5.4
- To remove exploring start assumption: on-policy and off-policy learning.
- ϵ-greedy policy on-policy MC control learning achieves the best policy among all ϵ-soft policies.
5.5
- The on-policy approach is actually a compromise – it learns action values not for the optimal policy, but for a near-optimal policy that still explores.
- π is target policy, b is behavior policy, both policies are considered fixed and given
- Assumption of coverage
- Almost all off-policy methods utilize importance sampling.
- Importance sampling: a general technique for estimating expected values under one distribution given samples from another
|visit|Item|Ordinary| Weighted | Comments | |—|—|—|—|—| |first-visit|biased|N: It is similar to E(V(pai))/Constant|Y: It also includes factor of Theta|Bias of weighted converge to 0| |first-visit|Variance| Extreme: as there is no constraint on b|Bounded: as max(Theta) <= 1|Variance of weighted converge to 0 providing bounded returns| |every-visit|biased|Y|Y|Bias falls to 0 in both cases|
5.7
The behavior policy b can be anything, but in order to assure convergence of π to the optimal policy, an infinite number of returns must be obtained for each pair of state and action. This can be assured by choosing b to be epsilon-soft.
Exercises
5.1
The last two rows represent 20 and 21 of player’s cards, which holds high possibility of winning of player. When sum < 20, the policy tells the player to hit. Then, when sum is small, player holds high possibility of losing game; when sum is large, player holds high possibility of bust.
The player and the dealer hold the same possibility of getting sum = {20, 21}. At left corner, the dealer holds Ace, which contributes high possibility of dealer winning for two reasons:
- Dealer can reach 20/21 by fewer steps. As more steps means larger sum and higher possibility of bust, fewer steps mean more possibility of 20/21.
- It reduces possibility of the case that the player holds Ace.
Similar reasons as listed above
5.2
No. Because the sum is allowed to be increased merely, no chance to be meet a state more than once in one episode
5.3
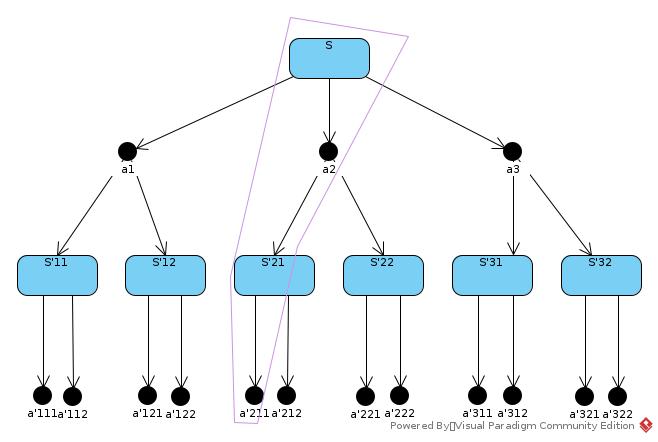
5.4
Qn(S, A) = ∑i=(1…n)Gi / n
= (∑i=(1…n - 1)Gi + Gn(S,A))/ n
= (Qn-1 * (n - 1) + Gn(S,A)) / n
= Qn-1 + (Gn(S,A) - Qn-1) / n
5.5
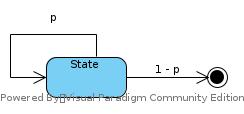
Gt = t ∀t
First-visit
State reached first at time t = 1, G1 = 1, v(s) = 1
Every-visit
State arrived 9 times with t = {1, 2, …, 9}
v(s) = ∑tGt / T : t = {1, 2, …, 9}, T = 9
= (1 + 2 + … + 9) / 9 = 5
5.6
The probability of subsequent trajectory is:
| Pr{St+1, At+1,St+2, At+2,…,ST | St+1,At:T-1} |
| = p(St+1 | St,At) * ∏k=t+1:T-1π(Ak | Sk)p(Sk+1 | Sk,Ak) |
| ρt = ∏k=t+1:T-1π(Ak | Sk)p(Sk+1 | Sk,Ak) / ∏k=t+1:T-1b(Ak | Sk)p(Sk+1 | Sk,Ak) |
| = ∏k=t+1:T-1π(Ak | Sk) / ∏k=t+1:T-1b(Ak | Sk) |
Q(s,a) = ∑tρtGt / ∑tρt
5.7
The bias of weighted average is explicit as the bias is also introduced by that of ρ. And, at the very beginning, ρ is also very biased.
5.8
Assume gk represent return for a trajectory with length = k from start point. gk = ρk * Returnk
For example, an episode with T = 2 includes a trajectory with length = 1 and trajectory with length = 2.
As Reward = 1 at the end of episode and γ = 1, an episode with (T + 1) steps would include T visit to S, each with return = 1. That is, for each episode with length = (T + 1), the V(s) is updated by (g1 + g2 + … + gT) / T
Assume pk = probability of an episode last for k
For all episode,
Sum = p1 * g1 + p2 * (g1 + g2) + …+ pT * ∑k=(1:T)gk
= ∑k=(1:T)pkg1 + ∑k=(2:T)pkg2 + … + gT
= ∑i=(1:T)gi∑k=(i:T)pk
To take average:
Average = ∑i=(1:T)gi * (1/i) ∑k=(i:T)pk
gi = 2i
pk = 0.9k
Average = ∑i=(1:T)(1/i) * 2i * 0.9i ∑k=(0:T-i)0.9k > ∑i=(1:T)(1/i) * 1.8i * Constant = INF
Then E(X2) > Average2 = INF
There would be still INF variance for every-visit
5.9
Modify figure in 5.6
Loop forever (for each episode):
b <- any policy with coverage of π
Generate episode following b: S0, A0, R1, ..., S(T-1),A(T-1),R(T)
G <- 0
W <- 1
Loop for each step of espisode, t = T-1, T-2, ..., 0 while (w != 0)
G <- γG + R(t+1)
If (S(t),A(t)) has not been touched in this episode:
C(S(t),A(t)) += W
Q(S(t),A(t)) += W/C * [G - Q(S(t),A(t))]
W *= π(A|S)/b(A|S)
Modify figure in 5.1
Initialize:
N(S) = 0, for all S
Loop forever (for each episode):
Generate episode following b: S0, A0, R1, ..., S(T-1),A(T-1),R(T)
G <- 0
visit(s) <- -1, for all s
g(t) <- 0, for all g
//They are to find first visit step in backward traverse
Loop for each step of espisode, t = T-1, T-2, ..., 0 while (w != 0)
G <- γG + R(t+1)
g(t) = G
visit(s) = t
Loop for each visit:
if (visit(s) >= 0):
N(s) += 1
V(s) += [g(visit(s)) - V(s)] / N(s)
5.10
Vn = ∑n-1(k)WkGk / ∑n-1(k)Wk
Vn+1 = ∑n(k)WkGk / ∑n(k)Wk
= (∑n-1(k)WkGk + WnGn) / ∑n(k)Wk
= (Vn * ∑n-1(k)Wk + VnWn + WnGn - VnWn) / ∑n(k)Wk
= (Vn * ∑n(k)Wk + Wn(Gn - Vn)) / ∑n(k)Wk
= Vn + Wn(Gn - Vn) / ∑n(k)Wk
= Vn + Wn(Gn - Vn) / Cn
5.11
Because π is a greedy policy, i.e., A = π(S) is a deterministic. And the algorithm says:
“If At != π(St then exit inner Loop (proceed to next episode)”.
So, π(At, St) = 1.